8.5 Container Management
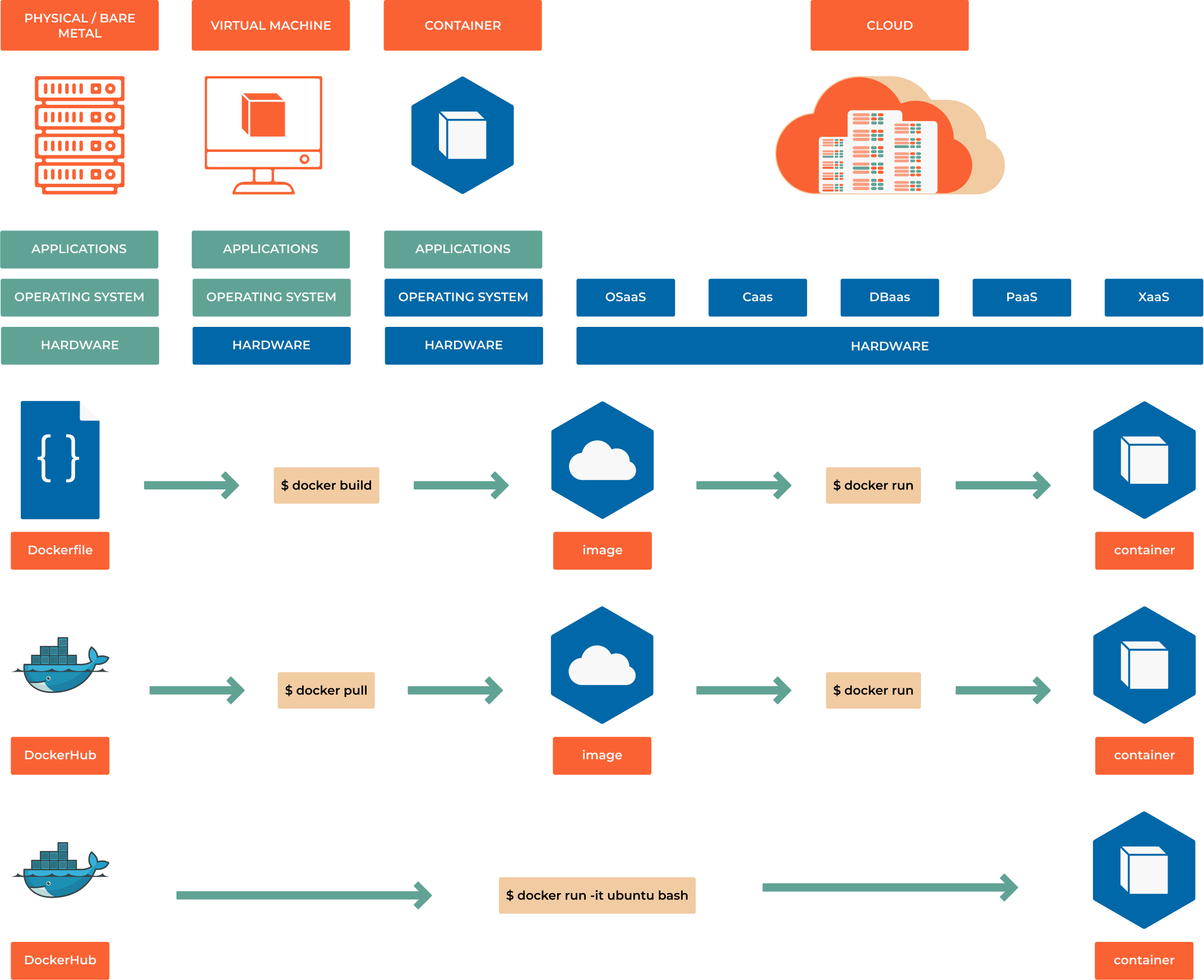
From Individual Containers to Managed Systems
Running individual containers is just the beginning. Production environments require sophisticated management strategies to handle dozens or hundreds of containers across multiple hosts. This section bridges the gap between basic container operations and full orchestration platforms.
You’ll learn to manage container lifecycles, implement monitoring, handle security, and establish operational patterns that scale from development to enterprise production.
Learning Objectives
By the end of this section, you will:
Identify the challenges of managing containers at scale
Implement container lifecycle management strategies
Configure logging, monitoring, and alerting systems
Apply security policies and access controls
Design service discovery and networking solutions
Establish backup, recovery, and disaster recovery procedures
Prerequisites: Solid understanding of container fundamentals, networking, and storage concepts
Challenges of Container Management
The Single Container Problem
While containers solve application packaging, running them in production introduces new challenges:
1. Ephemeral Nature
Containers are designed to be temporary
Application state can be lost
Configuration must be externalized
Data persistence requires careful planning
2. Security Concerns
Default configurations may be insecure
Image vulnerabilities require ongoing management
Runtime security monitoring is essential
Access control and secrets management needed
3. Network Complexity
Service discovery between containers
Load balancing across instances
Network segmentation and policies
Cross-host communication
4. Operational Overhead
Log aggregation and analysis
Health monitoring and alerting
Resource optimization
Version management and rollbacks
5. Scale Management - Manual scaling is error-prone - Resource allocation optimization - Failure handling and recovery - Cross-datacenter deployment
Note
The Management Spectrum: Container management tools exist on a spectrum from simple (Docker Compose) to complex (Kubernetes). Choose the right tool for your scale and complexity needs.
Container Lifecycle Management
Systematic Approach to Container Operations
1. Image Lifecycle Management
# Image versioning strategy
docker build -t myapp:1.2.3 .
docker build -t myapp:latest .
# Automated image scanning
trivy image myapp:1.2.3
# Image promotion pipeline
# dev → staging → production
docker tag myapp:1.2.3 registry.company.com/myapp:1.2.3-dev
docker tag myapp:1.2.3 registry.company.com/myapp:1.2.3-staging
docker tag myapp:1.2.3 registry.company.com/myapp:1.2.3-prod
2. Container State Management
# Graceful shutdown handling
docker stop --time=30 myapp # Give 30 seconds for graceful shutdown
# Health check configuration
docker run -d \
--name myapp \
--health-cmd="curl -f http://localhost:8080/health || exit 1" \
--health-interval=30s \
--health-timeout=10s \
--health-retries=3 \
myapp:1.2.3
# Restart policy for resilience
docker run -d --restart=unless-stopped myapp:1.2.3
3. Configuration Management
# docker-compose.yml with environment-specific configs
version: '3.8'
services:
app:
image: myapp:${VERSION:-latest}
environment:
- LOG_LEVEL=${LOG_LEVEL:-INFO}
- DATABASE_URL=${DATABASE_URL}
- API_KEY_FILE=/run/secrets/api_key
secrets:
- api_key
configs:
- source: app_config
target: /app/config.yml
configs:
app_config:
file: ./configs/${ENVIRONMENT:-dev}/app.yml
secrets:
api_key:
external: true
Logging and Monitoring
Centralized Logging Strategy
1. Log Collection Architecture
# Centralized logging with ELK stack
version: '3.8'
services:
# Application with structured logging
app:
image: myapp:latest
logging:
driver: "json-file"
options:
max-size: "10m"
max-file: "3"
labels: "service=myapp,environment=production"
depends_on:
- elasticsearch
# Elasticsearch for log storage
elasticsearch:
image: elasticsearch:8.11.0
environment:
- discovery.type=single-node
- xpack.security.enabled=false
volumes:
- elasticsearch_data:/usr/share/elasticsearch/data
# Logstash for log processing
logstash:
image: logstash:8.11.0
volumes:
- ./logstash.conf:/usr/share/logstash/pipeline/logstash.conf
depends_on:
- elasticsearch
# Kibana for log visualization
kibana:
image: kibana:8.11.0
ports:
- "5601:5601"
environment:
- ELASTICSEARCH_HOSTS=http://elasticsearch:9200
depends_on:
- elasticsearch
2. Structured Logging Implementation
# Python application with structured logging
import logging
import json
from datetime import datetime
class StructuredLogger:
def __init__(self, service_name):
self.service_name = service_name
self.logger = logging.getLogger(service_name)
handler = logging.StreamHandler()
handler.setFormatter(self.JSONFormatter())
self.logger.addHandler(handler)
self.logger.setLevel(logging.INFO)
class JSONFormatter(logging.Formatter):
def format(self, record):
log_data = {
'timestamp': datetime.utcnow().isoformat(),
'level': record.levelname,
'service': self.service_name,
'message': record.getMessage(),
'container_id': os.environ.get('HOSTNAME', 'unknown'),
'version': os.environ.get('APP_VERSION', 'unknown')
}
if hasattr(record, 'user_id'):
log_data['user_id'] = record.user_id
return json.dumps(log_data)
# Usage
logger = StructuredLogger('user-service')
logger.logger.info('User login successful', extra={'user_id': '12345'})
3. Monitoring and Alerting
# Prometheus monitoring stack
version: '3.8'
services:
# Prometheus for metrics collection
prometheus:
image: prom/prometheus:latest
ports:
- "9090:9090"
volumes:
- ./prometheus.yml:/etc/prometheus/prometheus.yml
- prometheus_data:/prometheus
command:
- '--config.file=/etc/prometheus/prometheus.yml'
- '--storage.tsdb.path=/prometheus'
- '--web.console.libraries=/usr/share/prometheus/console_libraries'
- '--web.console.templates=/usr/share/prometheus/consoles'
- '--web.enable-lifecycle'
# Grafana for visualization
grafana:
image: grafana/grafana:latest
ports:
- "3000:3000"
environment:
- GF_SECURITY_ADMIN_PASSWORD=admin
volumes:
- grafana_data:/var/lib/grafana
- ./grafana/dashboards:/etc/grafana/provisioning/dashboards
- ./grafana/datasources:/etc/grafana/provisioning/datasources
# AlertManager for alerting
alertmanager:
image: prom/alertmanager:latest
ports:
- "9093:9093"
volumes:
- ./alertmanager.yml:/etc/alertmanager/alertmanager.yml
4. Application Metrics Integration
from prometheus_client import Counter, Histogram, Gauge, generate_latest
import time
# Define metrics
REQUEST_COUNT = Counter('app_requests_total', 'Total requests', ['method', 'endpoint'])
REQUEST_DURATION = Histogram('app_request_duration_seconds', 'Request duration')
ACTIVE_CONNECTIONS = Gauge('app_active_connections', 'Active connections')
# Instrument your application
@REQUEST_DURATION.time()
def process_request(method, endpoint):
REQUEST_COUNT.labels(method=method, endpoint=endpoint).inc()
# Your application logic here
pass
# Metrics endpoint
@app.route('/metrics')
def metrics():
return generate_latest()
Security Management
Multi-Layer Security Strategy
1. Image Security
# Automated security scanning pipeline
#!/bin/bash
IMAGE_NAME=$1
SEVERITY_THRESHOLD="HIGH"
echo "Scanning $IMAGE_NAME for vulnerabilities..."
# Scan with Trivy
trivy image --format json --output scan-results.json $IMAGE_NAME
# Check for critical/high vulnerabilities
HIGH_VULNS=$(jq '.Results[]?.Vulnerabilities[]? | select(.Severity == "HIGH" or .Severity == "CRITICAL") | length' scan-results.json | wc -l)
if [ "$HIGH_VULNS" -gt 0 ]; then
echo " Found $HIGH_VULNS high/critical vulnerabilities"
jq '.Results[]?.Vulnerabilities[]? | select(.Severity == "HIGH" or .Severity == "CRITICAL")' scan-results.json
exit 1
fi
echo " Security scan passed"
2. Runtime Security
# Security-hardened container deployment
version: '3.8'
services:
app:
image: myapp:latest
user: "1001:1001" # Non-root user
read_only: true # Read-only root filesystem
tmpfs:
- /tmp:rw,noexec,nosuid,size=100m
security_opt:
- no-new-privileges:true
- seccomp:seccomp-profile.json
cap_drop:
- ALL
cap_add:
- NET_BIND_SERVICE # Only if needed
environment:
- MYSQL_ROOT_PASSWORD_FILE=/run/secrets/mysql_root_password
secrets:
- mysql_root_password
3. Network Security
# Create isolated networks
docker network create --driver bridge \
--subnet=172.20.0.0/16 \
--ip-range=172.20.240.0/20 \
frontend-network
docker network create --driver bridge \
--subnet=172.21.0.0/16 \
--internal \
backend-network
# Deploy with network segmentation
docker run -d \
--name web-app \
--network frontend-network \
-p 80:8080 \
web-app:latest
docker run -d \
--name database \
--network backend-network \
postgres:15
Service Discovery and Networking
Container Communication Strategies
1. DNS-Based Service Discovery
# Docker Compose automatic service discovery
version: '3.8'
services:
web:
build: .
environment:
- DATABASE_URL=postgresql://user:pass@db:5432/myapp
- REDIS_URL=redis://cache:6379
depends_on:
- db
- cache
db:
image: postgres:15
environment:
- POSTGRES_DB=myapp
- POSTGRES_USER=user
- POSTGRES_PASSWORD=pass
cache:
image: redis:alpine
2. Load Balancing with HAProxy
# haproxy.cfg
global
daemon
defaults
mode http
timeout connect 5000ms
timeout client 50000ms
timeout server 50000ms
frontend web_frontend
bind *:80
default_backend web_servers
backend web_servers
balance roundrobin
option httpchk GET /health
server web1 web-app-1:8080 check
server web2 web-app-2:8080 check
server web3 web-app-3:8080 check
# Load balancer deployment
version: '3.8'
services:
haproxy:
image: haproxy:alpine
ports:
- "80:80"
- "8404:8404" # Stats page
volumes:
- ./haproxy.cfg:/usr/local/etc/haproxy/haproxy.cfg
depends_on:
- web-app
web-app:
build: .
deploy:
replicas: 3
healthcheck:
test: ["CMD", "curl", "-f", "http://localhost:8080/health"]
interval: 30s
timeout: 10s
retries: 3
3. Service Mesh with Consul Connect
# Service mesh with Consul
version: '3.8'
services:
consul:
image: consul:latest
command: agent -server -bootstrap -ui -client=0.0.0.0
ports:
- "8500:8500"
volumes:
- consul_data:/consul/data
app:
image: myapp:latest
environment:
- CONSUL_HTTP_ADDR=consul:8500
depends_on:
- consul
labels:
- "consul.service=myapp"
- "consul.port=8080"
Backup and Recovery
Data Protection Strategies
1. Volume Backup Automation
#!/bin/bash
# backup-volumes.sh
BACKUP_DIR="/backups/$(date +%Y%m%d)"
mkdir -p $BACKUP_DIR
# Backup PostgreSQL data
docker exec postgres-db pg_dump -U postgres myapp > $BACKUP_DIR/postgres-backup.sql
# Backup volume data
docker run --rm \
-v postgres_data:/source:ro \
-v $BACKUP_DIR:/backup \
ubuntu tar czf /backup/postgres-volume.tar.gz -C /source .
# Upload to S3 (example)
aws s3 cp $BACKUP_DIR s3://my-backups/postgres/$(date +%Y%m%d)/ --recursive
# Cleanup old local backups (keep 7 days)
find /backups -type d -mtime +7 -exec rm -rf {} \;
2. Application State Backup
# Backup service in docker-compose
version: '3.8'
services:
backup:
image: postgres:15
volumes:
- postgres_data:/var/lib/postgresql/data:ro
- ./backups:/backups
environment:
- PGPASSWORD=mypassword
command: |
sh -c "
while true; do
pg_dump -h postgres -U postgres myapp > /backups/backup_$(date +%Y%m%d_%H%M%S).sql
find /backups -name '*.sql' -mtime +7 -delete
sleep 3600 # Backup every hour
done
"
depends_on:
- postgres
3. Disaster Recovery Procedures
#!/bin/bash
# disaster-recovery.sh
BACKUP_FILE=$1
if [ -z "$BACKUP_FILE" ]; then
echo "Usage: $0 <backup-file>"
exit 1
fi
echo "Starting disaster recovery..."
# Stop current services
docker-compose down
# Remove old volumes
docker volume rm postgres_data
# Recreate volumes
docker volume create postgres_data
# Restore database
docker run --rm \
-v postgres_data:/var/lib/postgresql/data \
-v $(pwd):/backup \
postgres:15 \
sh -c "
pg_ctl init -D /var/lib/postgresql/data
pg_ctl start -D /var/lib/postgresql/data
psql -U postgres < /backup/$BACKUP_FILE
pg_ctl stop -D /var/lib/postgresql/data
"
# Restart services
docker-compose up -d
echo "Disaster recovery completed"
Performance Optimization
Resource Management and Tuning
1. Resource Monitoring and Limits
# Monitor resource usage
docker stats --format "table {{.Name}}\t{{.CPUPerc}}\t{{.MemUsage}}\t{{.NetIO}}\t{{.PIDs}}"
# Set appropriate limits
docker run -d \
--name optimized-app \
--memory=512m \
--cpus="1.0" \
--pids-limit=100 \
--ulimit nofile=1024:2048 \
myapp:latest
2. JVM Tuning for Containerized Applications
# Optimized Java application
FROM openjdk:17-jre-slim
# Set JVM options for containers
ENV JAVA_OPTS="-XX:+UseContainerSupport \
-XX:MaxRAMPercentage=80 \
-XX:+UseG1GC \
-XX:+UseStringDeduplication \
-XX:+PrintGCDetails \
-Xlog:gc*:gc.log"
COPY app.jar /app.jar
CMD ["sh", "-c", "java $JAVA_OPTS -jar /app.jar"]
3. Database Connection Pooling
# PgBouncer for connection pooling
version: '3.8'
services:
pgbouncer:
image: pgbouncer/pgbouncer:latest
environment:
- DATABASES_HOST=postgres
- DATABASES_PORT=5432
- DATABASES_USER=postgres
- DATABASES_PASSWORD=mypassword
- DATABASES_DBNAME=myapp
- POOL_MODE=transaction
- MAX_CLIENT_CONN=100
- DEFAULT_POOL_SIZE=25
ports:
- "6432:6432"
depends_on:
- postgres
app:
image: myapp:latest
environment:
- DATABASE_URL=postgresql://postgres:mypassword@pgbouncer:6432/myapp
Container Registry Management
Private Registry Setup and Management
1. Local Registry Deployment
# Private Docker registry with security
version: '3.8'
services:
registry:
image: registry:2
ports:
- "5000:5000"
environment:
- REGISTRY_AUTH=htpasswd
- REGISTRY_AUTH_HTPASSWD_REALM=Registry Realm
- REGISTRY_AUTH_HTPASSWD_PATH=/auth/htpasswd
- REGISTRY_STORAGE_FILESYSTEM_ROOTDIRECTORY=/var/lib/registry
volumes:
- registry_data:/var/lib/registry
- ./auth:/auth
restart: unless-stopped
registry-ui:
image: joxit/docker-registry-ui:latest
ports:
- "8080:80"
environment:
- REGISTRY_TITLE=My Private Registry
- REGISTRY_URL=http://registry:5000
depends_on:
- registry
2. Image Lifecycle Management
# Image cleanup script
#!/bin/bash
REGISTRY_HOST="localhost:5000"
DAYS_TO_KEEP=30
# Get all repositories
REPOS=$(curl -s http://$REGISTRY_HOST/v2/_catalog | jq -r '.repositories[]')
for repo in $REPOS; do
echo "Processing repository: $repo"
# Get all tags
TAGS=$(curl -s http://$REGISTRY_HOST/v2/$repo/tags/list | jq -r '.tags[]')
for tag in $TAGS; do
# Get manifest
DIGEST=$(curl -s -H "Accept: application/vnd.docker.distribution.manifest.v2+json" \
http://$REGISTRY_HOST/v2/$repo/manifests/$tag | jq -r '.config.digest')
# Get creation date
CREATED=$(curl -s http://$REGISTRY_HOST/v2/$repo/blobs/$DIGEST | jq -r '.created')
CREATED_TIMESTAMP=$(date -d "$CREATED" +%s)
CUTOFF_TIMESTAMP=$(date -d "$DAYS_TO_KEEP days ago" +%s)
if [ $CREATED_TIMESTAMP -lt $CUTOFF_TIMESTAMP ]; then
echo "Deleting old image: $repo:$tag"
curl -X DELETE http://$REGISTRY_HOST/v2/$repo/manifests/$tag
fi
done
done
Migration Strategies
Moving from Legacy Systems to Containers
1. Strangler Fig Pattern
# Gradual migration with proxy routing
version: '3.8'
services:
# Legacy application
legacy-app:
image: legacy-app:latest
ports:
- "8081:8080"
# New containerized service
new-service:
image: new-service:latest
ports:
- "8082:8080"
# Proxy for gradual migration
nginx:
image: nginx:alpine
ports:
- "80:80"
volumes:
- ./nginx-migration.conf:/etc/nginx/nginx.conf
depends_on:
- legacy-app
- new-service
2. Blue-Green Deployment
#!/bin/bash
# blue-green-deploy.sh
NEW_VERSION=$1
CURRENT_COLOR=$(docker inspect --format='{{.Config.Labels.color}}' production-app 2>/dev/null || echo "blue")
NEW_COLOR=$([ "$CURRENT_COLOR" = "blue" ] && echo "green" || echo "blue")
echo "Current: $CURRENT_COLOR, Deploying: $NEW_COLOR"
# Deploy new version
docker run -d \
--name production-app-$NEW_COLOR \
--label color=$NEW_COLOR \
--network production \
myapp:$NEW_VERSION
# Wait for health checks
echo "Waiting for health checks..."
for i in {1..30}; do
if docker exec production-app-$NEW_COLOR curl -f http://localhost:8080/health; then
break
fi
sleep 5
done
# Switch traffic
echo "Switching traffic to $NEW_COLOR"
# Update load balancer configuration
# Remove old deployment
docker stop production-app-$CURRENT_COLOR
docker rm production-app-$CURRENT_COLOR
echo "Deployment completed successfully"
What’s Next?
You now understand the complexities and solutions for managing containers at scale. The next section covers container orchestration with Docker Compose and introduces concepts that lead to Kubernetes for enterprise-scale deployments.
Key takeaways:
Container management involves lifecycle, security, monitoring, and networking
Centralized logging and monitoring are essential for production operations
Security must be implemented at multiple layers
Service discovery and load balancing enable scalable architectures
Backup and recovery procedures are critical for data protection
Performance optimization requires resource limits and application tuning
Warning
Operational Readiness: The complexity of container management grows exponentially with scale. Invest in automation, monitoring, and documentation before you need them.